
Most product decisions are still made one of two ways:
- You rely on intuition and debate
- Or you ship something and wait to see what happens
Both approaches are slow. Both are expensive. And both assume you can afford to be wrong in production.
Simulation offers a third path - understand what will happen before you ship? But that only works if one question is answered - how closely does the simulation reflect real user behavior. That's what we call behavioral fidelity.
Outcomes aren’t enough
Many systems evaluate success at the surface level:
- Did the user complete the task?
- Did they click the button?
But two systems can produce the same outcome for completely different reasons. What matters isn’t just what users do, it's how they decide what they do. That decision matrix is what we're optimizing for when we're evaluating experiments and their impact at blok.
Fidelity is about matching behavior, not just results
We define fidelity as how closely simulated decisions match real user behavior at each step of an interaction.
Formally, we’re interested in whether:
P(agent action | state) ≈ P(real user action | state)
We measure this across many states, many users, and we're looking at full interaction trajectories. After all, this is a distributional problem, not a single predcition problem.
Why distributions matter
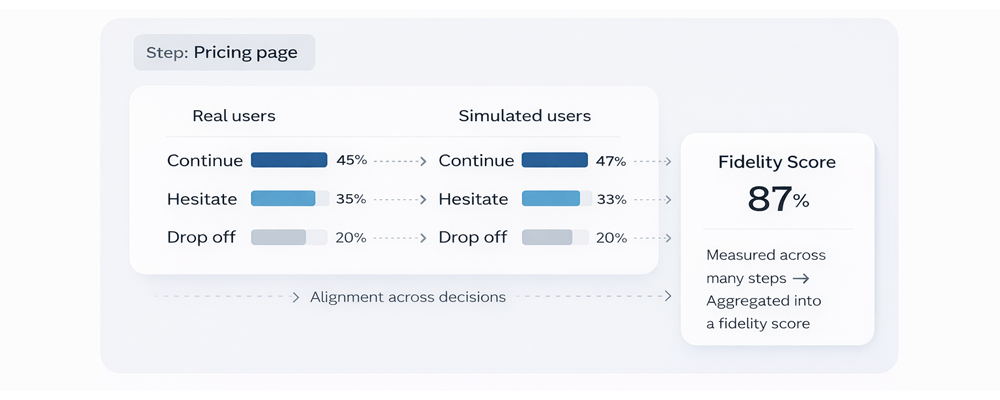
Real user behavior is not deterministic. At any given step, some users will continue, some will likely hesitate and some will drop off. Fidelity isn't 'did we predict the right outcome?', it's 'do we reproduce the same distribution of decisions at any given time across many different users?'
The three components of fidelity
We measure this using three statistically grounded components:
1. Decision-level alignment
For each state s, we compare:
P_agent(a | s) vs P_user(a | s)
Where a = possible actions (click, scroll, drop-off, etc.). We measure how closely these distributions align across many states.
2. Intra-trajectory coherence
Given a trajectory:
τ = (s₁ → a₁ → s₂ → a₂ → ... → sₙ)
We evaluate whether the sequence of actions is consistent, behaviorally plausible, and aligned with real user patterns. This avoids erratic behavior, mode collapse and unrealistic jumps.
3. Inter-run stability
For repeated simulations:
τ₁, τ₂, ..., τ_k
We check whether:
Var(P_agent(a | s)) is bounded across runs
What this means, is results are reproducible, distributions will converge, and behavior doesn't drift randomly.
From components to a single score
These are combined into a fidelity score:
Fidelity = f(alignment, coherence, stability)
This fidelity score reflects the statistical alignment with real users, consistency across decisions, and most importantly the reproducibility across runs.
Backtesting: does it match reality?
Most importantly though, we validate fidelity through backtesting. We do this by comparing simulated behavior to historical data, across real product flows and with real, differentiated user segments. The key question we're asking as we're evaluating, is does this reproduce what actually happened?
Forward testing: does it predict the future?
But backtesting alone isn’t enough.
We also run forward validation. What we're doing here, is simulating behavior on new changes, and comparing predictions to real outcomes after they've launched. This allows us to test generalization and our ability to successfully predict, as opposed to memorization of historic events.
Held-out validation
To ensure rigor:
- We evaluate against held-out user data
- Not used during training
- Not seen during simulation
If:
|P_agent - P_user| > tolerance
well, then the model fails evaluation.
Why this matters
Fidelity determines whether you can trust the system.
High fidelity means:
- you can identify real friction points before launch
- you can evaluate changes without user risk
- you can reduce wasted engineering effort
Across real-world evaluations, this approach achieves up to 87% behavioral fidelity - meaning simulated users make decisions that closely match how real users behave across full product flows.
Because this is measured at the level of individual decisions, validated against held-out data, and tested for stability across runs, it provides a reliable signal teams can use to make product decisions before anything goes live.
Simulation without fidelity is just output. Simulation with fidelity becomes a reliable input into product decisions.